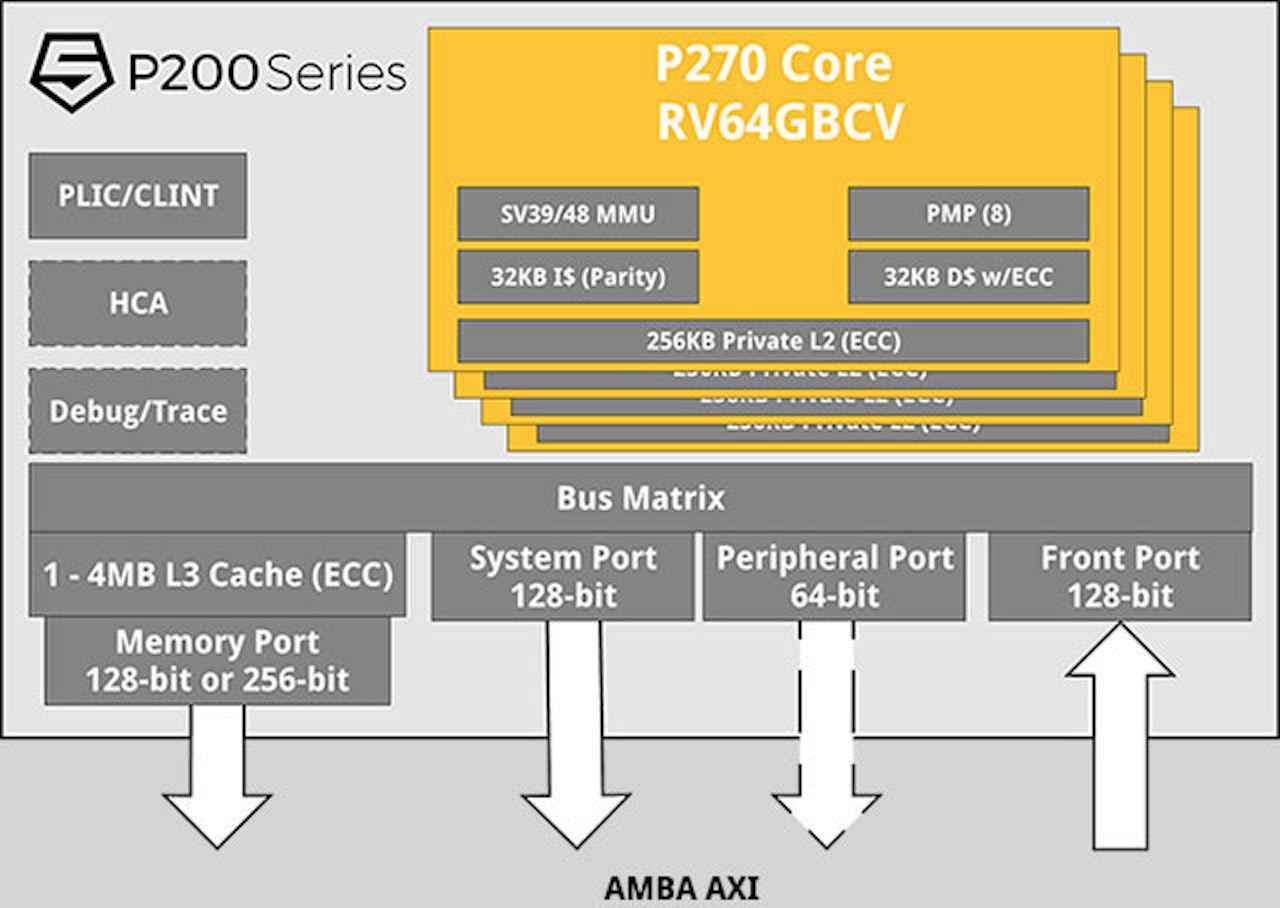
SiFive Performance
P270
The SiFive Performance™ P270 is an 8-stage, dual-issue, highly efficient in-order pipeline compatible with the RISC-V RV64GBCV ISA. With full support for the RISC V Vector Extension 1.0, and combined with the popular SiFive Recode utility, which translates existing SIMD software from popular legacy architectures to RISC-V Vector assembly code, the P270 is an ideal replacement for dated SIMD architectures.

SiFive Performance Family
The SiFive Performance family of RISC-V processors is designed for maximum throughput, while preserving power efficiency for workloads as varied as branch-intensive operating systems, and multimedia processing. Ranging from 8-stage, dual-issue, in-order architectures equipped with 256-bit vector engines, to advanced three and four-issue out-of-order processors, with and without vector compute capabilities, with best-in-class industry benchmark performance, the SiFive Performance Family represents the future of compute.
SiFive Performance
P270 Key Features
- 256-bit vector length processor
- Variable length operations, up to 256-bits of data per cycle, with dynamic vector length configuration
- Ideal balance of control and data parallel compute - Performance benchmarks
- 5.75 CoreMarks/MHz
- 3.25 DMIPS/MHz
- 4.6 SpecINT2k6/GHz - Scalar processing built from U7 series core
- Multi-layer Caching support for optimum data movement
- Stride Prefetcher
- Virtual memory support, up to 48-bit addressing - High performance, flexible connectivity to SoC peripherals
- Implements RISC-V Vectors v1.0
- Dual issue scalar unit runs concurrently with vector unit
- Key vector unit attributes
- VLEN = 256. DLEN = 128 (datapath width). ELEN = 64 (datatypes)
- Separate memory and ALU pipelines for concurrent operation
- Vector operations, decoded and queued in Vector Unit for parallel operation of Scalar and Vector units - Vector ALU
- 128b ALU can perform 2x64b, 4x32b, 8x16b, 16x8b ops/cycle
- Integer and Floating point data types supported - Vector Loads/Stores are 128b/cycle
- L2 cache treated as primary memory
- Load from L1 cache, initiates L2 cache load in parallel, minimizing L1 cache miss impact - Multi-core, multi-cluster processor configuration, up to 8 cores