SiFive Intelligence
XM Series
SiFive’s new XM Series offers an extremely scalable and efficient AI compute engine. By integrating scalar, vector, and matrix engines, XM Series customers can take advantage of very efficient memory bandwidth. The XM Series also continues SiFive’s legacy of offering extremely high performance per watt for compute-intensive applications. To speed up development time, SiFive is also open sourcing the SiFive Kernel Library.

SiFive Intelligence Family
- High-performance AI dataflow processor with scalable vector compute capabilities.
- AI workloads, data flow management, object detection, speech and recommendation processing.
SiFive Intelligence
XM Series Key Features
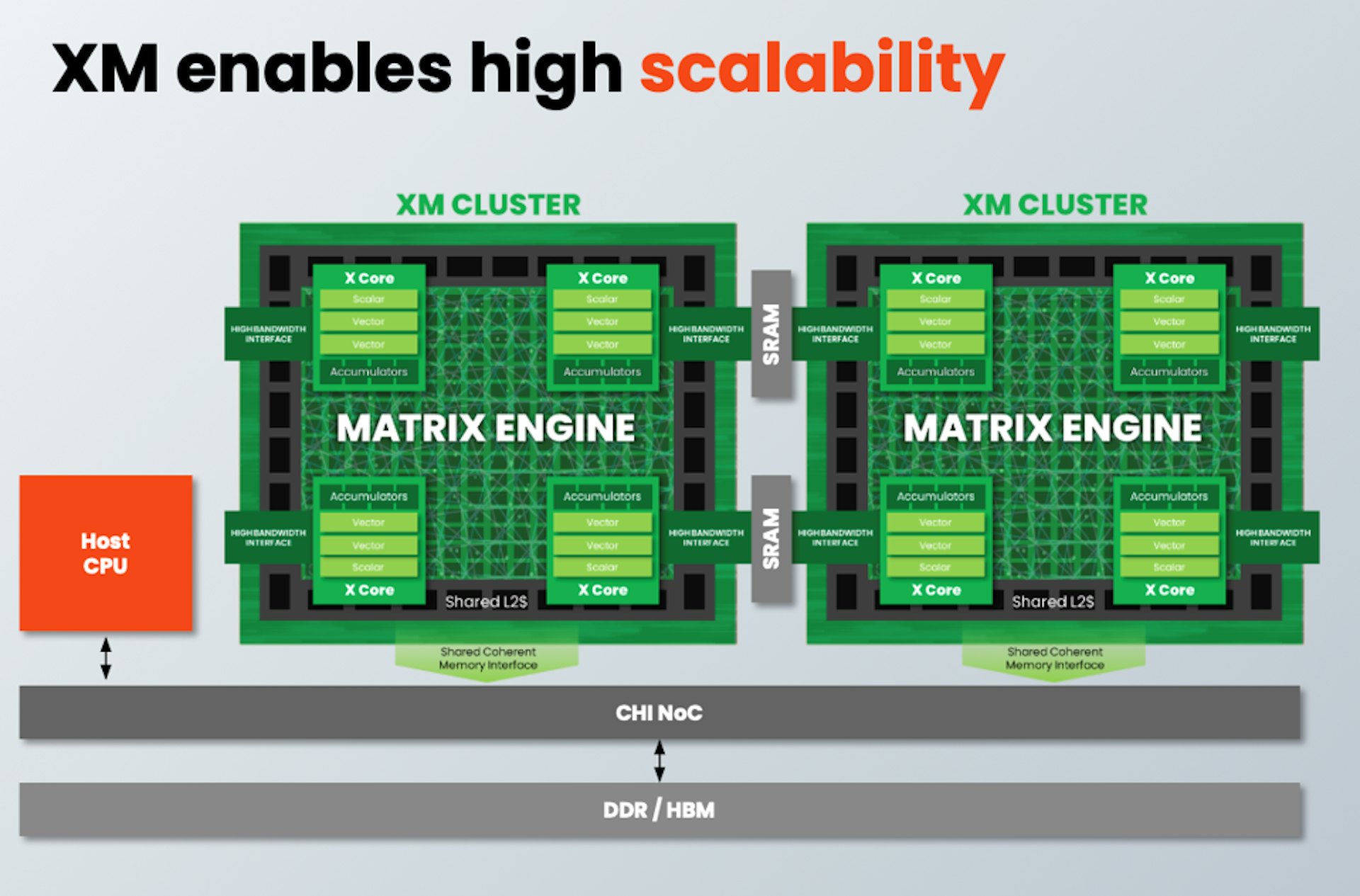
- SiFive Matrix Engine
- Fat Outer Product design
- Tightly integrated with 4 X-Cores
- Deep fusion with vector units - 4 X-Cores per cluster
- Each with dual vector units
- Executes all other layers e.g. activation functions
- New exponential acceleration instructions - New matrix instructions
- Fetched by scalar unit
- Source data comes from vector registers
- Destination to each matrix accumulator - 1 Cluster = 16 TOPS (INT8), 8 TFLOPS (BF16) per GHz
- 1TB/s sustained bandwidth per XM Series cluster
- XM clusters connect to memory in 2 ways:
- CHI port for coherent memory access
- High bandwidth port connected to SRAM for model data - Host CPU can be RISC-V, x86 or Arm (or not present)
- System can scale across multiple dies using CHI
 XM Enables High Scalability
XM Enables High Scalability